
Die Veröffentlichungen von Wissenschaftlerinnen und Wissenschaftlern zeigen, mit wem sie zusammenarbeiten und forschen. Das kann man sich zunutze machen. Aus der Liste der jeweiligen Co-Autorinnen und Co-Autoren eines Forschungsberichts lässt sich ein soziales Netzwerk konstruieren und analysieren. In diesem Beitrag zeige ich, wie man zentrale Personen aus einem Co-Autorennetzwerk ermitteln kann. Für die Visualisierung und Netzwerkanalyse nutze ich die Statistiksoftware R und das R-Paket „igraph“.
Forschungsarbeiten sind in der Regel das Ergebnis vieler Köpfe
Urban Farming oder auch Urban Agriculture ist ein Bereich, für den ich mich schon seit einiger Zeit interessiere – privat und aus wissenschaftlicher Perspektive. Die Forschung in diesem Bereich hat zwar schon eine lange Tradition, erlebt aber erst in den letzten Jahren einen Aufschwung. Wie ich weiß, beschäftigen sich viele Wissenschaftsdisziplinen inzwischen damit. Aber welche Wissenschaftler oder Wissenschaftlerinnen sind maßgeblich daran beteiligt? Die Analyse von Co-Autorennetzwerken kann helfen, diese Frage zu beantworten.
Wie eine solche Netzwerkanalyse aussehen kann, zeige ich anhand der COST Action Urban Agriculture Europe. Dieses Netzwerk ist als Beispiel gut geeignet. Es lässt sich relativ gut abgrenzen und hat für die Analyse eine übersichtliche Größe. Außerdem können die Daten noch gut mit der Hand erfasst werden. Bei umfangreicheren Analysen können Literaturverwaltungsprogramme bzw. Referenzmanager wie Citavi die Datensammlung unterstützen.
COST Action – Networking für Wissensschaffende
Um die Vernetzung über fachliche und nationale Grenzen hinaus zu unterstützen, fördert die EU sogenannte COST Actions (European Cooperation in Science and Technology). Diese dienen als Netzwerkinstrument für Wissensschaffende und Lehrende und sind eine Säule der europäischen Forschungszusammenarbeit.
Das Netzwerk COST Action Urban Agriculture Europe hat eine solche Förderung bereits erhalten. Davon profitiert haben mehr als 120 Forschende aus 26 Ländern, die sich darin zusammengefunden haben. Ihr Ziel: Grundlegende Definitionen für die urbane Landwirtschaft zu entwickeln und zukünftige Forschungsrichtungen zu diskutieren.
Die Ergebnisse der einzelnen Arbeitsgruppen sind 2015 in einem gemeinsamen Buch „Urban Agriculture Europe – the book“ veröffentlicht worden. Die darin enthaltenden Berichte inkl. ihrer Autoren und Autorinnen dienen hier als Grundlage für das Beispiel der Netzwerkanalyse.
Knoten und Kanten – Zuerst die Daten…
Ein soziales Netzwerk besteht in der Regel aus Personen (auch Knoten genannt, engl. nodes) und ihren Beziehungen zueinander (auch Kanten genannt, engl. edges). Das gilt auch für ein Co-Autorennetzwerk.
Die Analyse des Co-Autorennetzwerks beruht dabei auf folgender Annahme: Alle an einer Publikation beteiligten Personen, die als Co-Autor/in genannt werden, stehen in einer Beziehung zueinander. Ein fiktiver Forschungsbericht mit den drei Autorinnen A, B und C (nodes) macht das anschaulich. Aus der Lsite der Autorinnen lassen sich folgende drei Verbindungen (edges) formal darstellen: A – B, A – C und B – C. In dieser Form aufgeschrieben, ist die Aufzählung bereits eine sogenannte Edgelist bzw. Kantenliste.
Erfasst man in einem Co-Autorennetzwerk alle Verbindungen auf diese Weise, erhält man eine einfache aber grundlegende Edgelist, auf der man die Netzwerkanalyse aufbauen kann.
Für die hier folgende Analyse habe ich die Co-Autorinnen und Co-Autoren aus 18 Berichten des o. g. Buches (Kapitel 1-6, ohne Einführungstexte) per Hand in einer CSV-Datei (bzw. TXT-Datei) erfasst.
Achtung: Schon bei der Erfassung der Namen ist unbedingt auf eine richtige und einheitliche Schreibweise zu achten. Das verhindert u.a., dass einzelne Personen aufgrund unterschiedlicher Schreibweisen mehrfach gezählt werden.
… dann die Analyse – Vorbereitungen
Die nachfolgenden Schritte sind im Wesentlichen mit der Statistiksoftware R sowie dem R-Paket „igraph“ durchgeführt. Dabei gehe ich davon aus, dass Grundlagen im Umgang mit R bei den Leserinnen und Lesern bereits vorhanden sind. Dennoch versuche ich, ein möglichst einfachen Code zu entwickeln. Fragen und Anmerkungen dazu sind gerne willkommen.
Der Code für die folgenden Überlegungen kann hier heruntergeladen werden:
R-Code_Zentrale_Autoren_ermitteln
Übrigens, ein sehr ausführliches Skript über die Netzwerkanalyse und die Visualisierung mit R und igraph (engl.) hat die Kommunikationswissenschaftlerin Katherine Ognyanova erstellt. Es kann von ihrer Webseite runtergeladen werden. Teile dieses Blog-Beitrags sind davon inspiriert.
Doch nun ans Werk: Bevor man aus den Namen der Co-Autoren und Co-Autorinnen ein Co-Autorennetzwerk erstellt, müssen die Daten vorbereitet und aufbereitet werden. Obwohl ich bei der Erfassung der Namen schon sorgfältig war, habe ich R vorsichtshalber noch einmal überflüssige Leerzeichen beseitigen lassen (mit „str_trim“ aus dem Paket „stringr“).
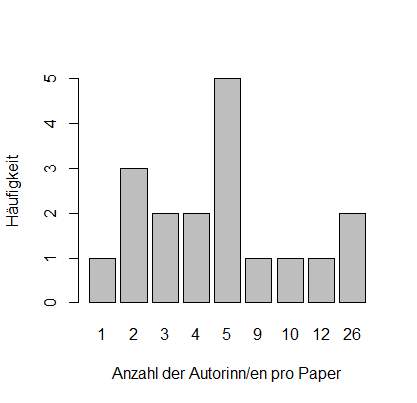
Die ersten Auswertungen ergeben, dass insgesamt 65 Personen an den 18 Berichten mitgeschrieben haben („unique_authors“). Davon sind ein Autor an 6 Berichten (Paper) und zwei Autorinnen jeweils an fünf Berichten beteiligt. Bei der Anzahl der Autoren pro Paper gibt es eine große Bandbreite (siehe Abbildung 1). Bei zwei Berichten sind 26 Beteiligte genannt.
Erstellen der Edgelist bzw. Kantenliste in R
Um die Edgelist (s. o.) des vorliegenden Co-Autorennetzwerks zu erstellen, verwende ich im R-Skript eine Schleife (Loop) mit der Anweisung „combn“. Damit wandelt R die Autorenliste jedes Papers in eine kurze Edgelist um und fügt sie zum Gesamtnetzwerk („net.edges“) zusammen.
Anmerkung: Publikationen mit vielen Co-Autorinnen und Co-Autoren können zu Verzerrungen bei der Berechnung führen. Deshalb habe ich alle Paper meines Beispiels auf fünf Beteiligte beschränkt und Paper mit weniger als zwei Beteiligten ganz ausgelassen.
Diese Einschränkung dient auch der besseren Darstellung des Netzwerkes. Dadurch vermindert sich allerdings die Anzahl der Personen auf 48 und die Zahl der Paper auf 17. Das ist bei der Interpretation der Ergebnisse zu beachten.
Die Visualisierung des Co-Autorennetzwerkes
Aus einer Edgelist kann das igraph-Paket den Graphen des Netzwerkes erstellen. Für die Visualisierung (siehe Abbildung 2) und die weiteren Analysen hat igraph noch Mehrfachverbindungen und mögliche Selbstbezüge entfernt (mit „simplify“).
Die Visualisierung des bereinigten COST-Graphen zeigt, dass das Gesamtnetzwerk aus vier nicht miteinander verbundene Komponenten besteht. Die Zahl und die Struktur einzelner Netzwerkkomponenten sagen bereits etwas über das Netzwerk aus. In der Netzwerktheorie ist beispielsweise der Informationsaustausch zwischen den unverbundenen Komponenten eher unwahrscheinlich. In der Praxis des COST-Netzwerkes hat er jedoch sicher stattgefunden.

Zentralitätsmaße im Co-Autorennetzwerk berechnen
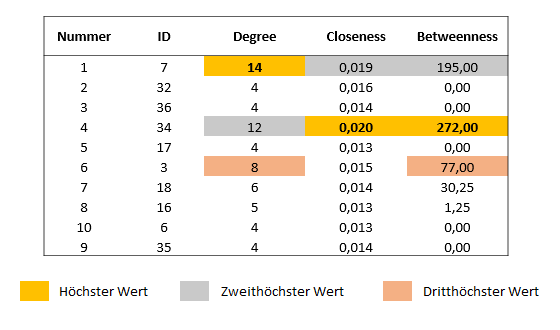
An der Visualisierung des Co-Autorennetzwerks kann man bereits auch mit bloßem Auge erkennen, dass einige Personen im Netzwerk eine besondere Stellung einnehmen. Die Personen mit den IDs 7 und 34 scheinen beispielsweise an einer zentralen Stelle zu stehen.
Diese besondere Stellung kann man auch mit Hilfe verschiedener Maßzahlen bestimmen. Weil unverbundenen Komponenten eines Netzwerkes für die Berechnung der Maßzahlen jedoch Schwierigkeiten machen können, schaue ich im Folgenden nur auf die größte der vier Komponenten. In ihr sind 31 Autorinnen und Autoren mehr oder weniger stark verbunden. Die Ergebnisse der Berechnungen sind unten in Tabelle 1 dargestellt.
Eine der möglichen Maßzahlen zur Bestimmung zentraler Personen ist die Degree-Zentralität. Sie gibt die Anzahl der Verbindungen eines Knotens im Netzwerk an, d. h. wie häufig diese Person vernetzt ist. Personen, die in diesem Beispiel entweder an vielen Publikationen mitgearbeitet haben oder an Publikationen mit vielen Beteiligten, haben die meisten Verbindungen. Aber Achtung: Die Anzahl der Beziehungen sagt nichts über die Qualität der Verbindungen bzw. Beziehungen aus! Deshalb sind weitere Kennzahlen sinnvoll.
Nähezentralität und Zwischenzentralität
Auch die Position einer Person im Netzwerk kann Aufschlüsse über ihre Bedeutung liefern. So berücksichtigt die Nähezentralität (Closeness Centrality) beispielsweise auch die indirekten Verbindungen. Sie ist als durchschnittliche Nähe einer Person im Netzwerk zu allen anderen Mitgliedern des Netzwerkes definiert. Informationen von Personen mit einer guten Nähezentralität können theoretisch alle Netzwerkmitglieder auf möglichst kurzem Weg erreichen.
Geht man davon aus, dass Informationen sich im Netzwerk ähnlich wie bei dem Spiel „Stille Post“ von Person zu Person verbreiten, dann haben wieder andere Netzwerkmitglieder einen Vorteil. Diejenigen, die ein hohes Maß an Zwischenzentralität (Betweenness Centrality) aufweisen, sind an der Informationsverbreitung beispielsweise maßgeblich beteiligt. Sie können unter anderem Teile eines Netzwerkes überbrücken, die ohne sie unverbunden wären. Beispiel: Wenn Informationen nur von A über B nach C gelangen, kann A ohne B den C nicht erreichen. B hat in diesem Fall also ein hohes Maß an Zwischenzentralität.
In Tabelle 1 sind die Maßzahlen der größten Netzwerkkomponente dargestellt. Während die Person mit der ID 7 bei der Anzahl der Verbindungen sehr gut abschneidet, hat die Person mit der ID 34 höhere Zentralitätsmaße bei Closeness und Betweenness. Dennoch: Beide Personen scheinen im hier untersuchten Co-Autorennetzwerk besonders zentral zu sein.
Fazit der Netzwerkanalyse
In diesem Beitrag habe ich das Co-Autorennetzwerk der COST Action Urban Agriculture Europe mit R und igraph untersucht. Anhand der beispielhaften Visualisierung und einiger Maßzahlen lassen sich für dieses Netzwerk bestimmte Zusammenhänge und zentrale Personen gut ermitteln.
Dabei zeigt sich: Nicht nur die Anzahl der Verbindungen einer Person ist entscheidend für ihre Zentralität, sondern auch ihre Stellung im Netzwerk.
Bei der Entwicklung des eigenen Netzwerks kann man sich diese Zusammenhänge auch zunutze machen. Manchmal reicht es eben aus, jemanden zu kennen, der oder die jemanden kennt. Oder anders, man muss nicht sehr viele Kontakte haben, um vom Netzwerk zu profitieren.
Über Anregungen und Anmerkungen in den Kommentaren würde ich mich sehr freuen.